Imagine that the team interfaces with an experienced PO who comes from an end-user community, has a lot of client-facing product management experience, fully understands principles of Agile product development, does not tolerate waste, appreciates benefits of incremental value delivery, is fully empowered, and knows how to effectively partner up with technology. Oh … and imagine this: Both the team and the PO are properly incentivized to work together toward the same
common goals and interests. Would it not be great if every company out there was like this?!
As the PO decomposes larger chunks of work (epics) into more manageable pieces (stories), he preserves relationships between epics and stories. Why does he do that? Well, this is what helps a PO retain a strategic view for the entire product; this is also how he manages his product road map. Some epics span multiple sprints (some are large) and, while individual stories still get delivered “per sprint” (meeting the Definition of Done for each sprint), the PO decides to go to production only when some important epics are done in full. At a glance, this may seem not the most Agile approach, but from a strategic perspective it does make sense to the PO: He must consider costs and overhead associated with synchronization of delivery from multiple Scrum teams, efforts associated with communication to and training of the end-user community, etc.
The PO well understands principles of economics of Lean product development and has done a great job in the past of optimizing batch size of new features and functionalities before they were rolled out to production. Time goes by … and the team completes a few sprints and establishes some velocity. This means that now the team knows its “burn rate.” Now if the team got a scope, it would be able to forecast when all known work could be done. It would probably produce a “cone of uncertainty” that would be equal to the gap between optimistic and pessimistic forecasting. The opposite would be true too: If a team were given a fixed release date, they could inversely forecast how much work could be done in that time (again, a “cone of uncertainty” would be present). Further, every team member knows from his/her past work experience how to apply story pointing techniques to estimate work, and this makes story estimation during PBRs and planning a pleasant exercise for the whole team because there is no fighting, no estimate padding, no resistance, no “CYA.” However, since a team does not release to production at the end of every sprint, the PO wants to be able to forecast on a time scale that is broader than a single sprint (across multiple sprints). In other words, the PO wants to know how many sprints (given a team’s burn rate) it may take before all of his intended scope will be done. The PO wants to know when he will be able to deliver a product to end users. However, it turns out that he cannot do so reliably. Why?
Note: In simple Scrum (individual team(s) working on a separate product), not releasing to production at the end of every sprint is not desirable. Unfortunately, at enterprise-size companies, with many post-development activities that “must happen,” releasing to production at the end of every sprint is challenging. Also, in scaled Scrum (LeSS, Nexus), with many teams working on the same product, it is frequently a conscious strategic business decision to release to production only after a few sprints worth of development (by multiple teams) are complete. It is important to remember that although a team may not be required/able to release to production at the end every release, it still must produce a potentially shippable product. Waiting for “collective deployment” is not an excuse to produce partially done work.
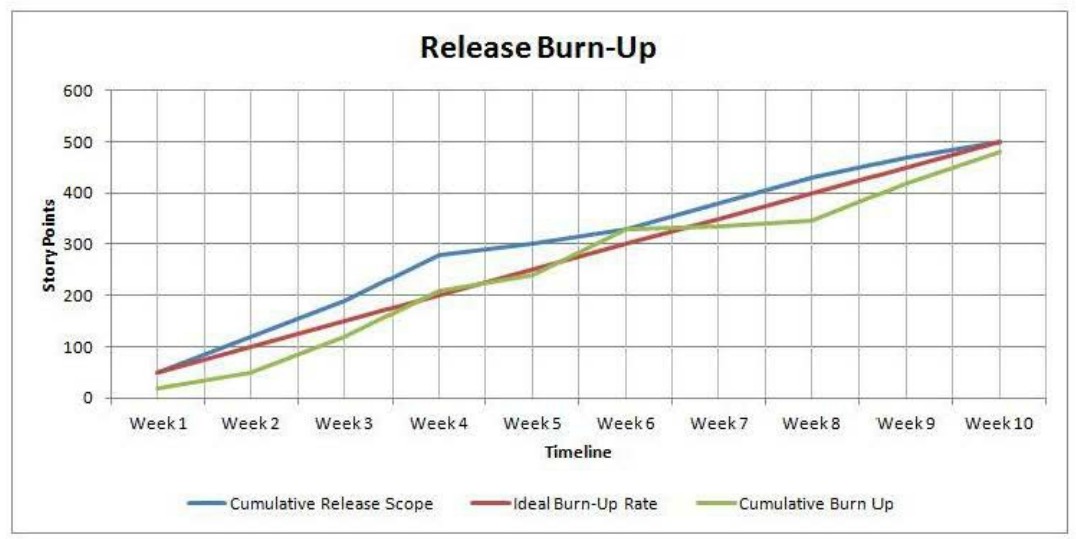
In a case like this, here is how the Release Burn-Up chart looks with respect to a scope:
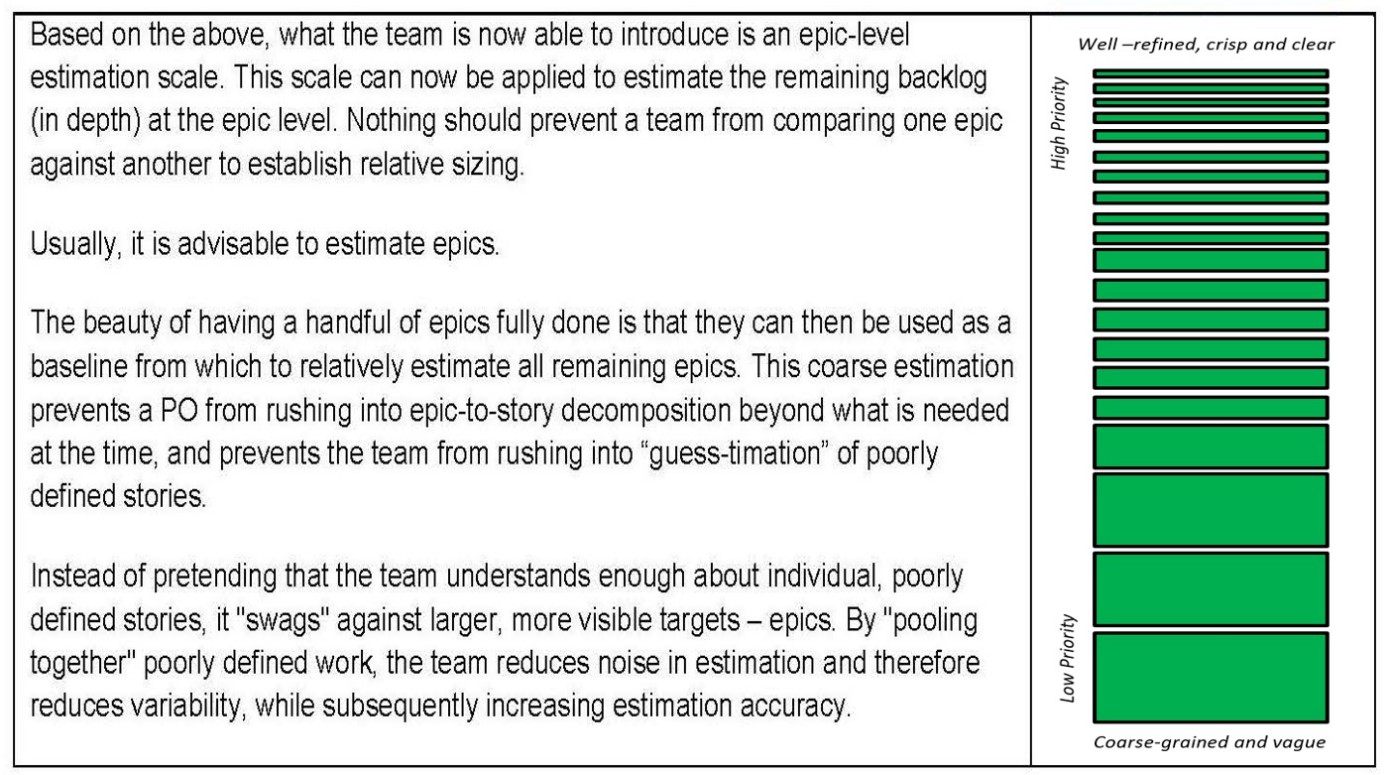
backlog in depth, because what is at the bottom of a backlog is not groomed well enough, and any attempt at esti‐ mating vaguely defined and not well-groomed stories would increase the margin of error and unwanted variability.”
And you are right again: Estimating an entire backlog based on poorly defined stories is unreliable and wasteful. If the PO asks the team to provide estimates that are based on a low level of understanding, he will eventually end up communicating unreliable dates to his end users and stakeholders. This will probably lead to finger-pointing, blame gaming, and a deteriorated reputation on the side of both business and technology.
Well, there might be a way.
On the other hand, the team is composed of experienced Scrummers who, after sprinting together for a while, have developed a good shared understanding of each other’s complexity-estimation style. Therefore, their estimation scale is reliable too. In other words, for this team, a 13-story-points user story most of the time proves to be bigger
than an 8-story-points user story, which is bigger than a 5-story-points user story, and so on. In other words, the team’s estimation scale is reliable.
This is what can come next:
- If Epic A is composed of ten stories (of various complexity) totaling, let’s say, 50 story points, then it would be fair to say that Epic A is 50 story points.
- By using the same logic, if Epic B is composed of 15 stories totaling 80 story points, then Epic B = 80 story points.
- The same goes for completed Epic C, Epic D, and so on.
Many teams prefer not to estimate epics on par with smaller stories, specifically to emphasize that the former are much larger than the latter and the two are not comparable. Teams frequently use a Small (S), Medium (M), Large (L), Huge (H) scale to estimate epics—this is faster and cheaper. But for teams that have a good track record of decomposing epics into stories and completing individual stories, and by doing so completing epics, another opportunity presents itself.
Leveraging the “reverse mathematics” described above, a team can now not only compare new epics by using the S- M-L-H scale but also compare new epics to completed epics and “normalize” the S-M-L-H scale to story points scale, without actually “guess-timating” new epics in story points. Again, in order for this to work, a team must have a good track record of breaking down epics into stories, estimating and completing individual stories and maintaining initial relationships between epics and stories.
But there is something to watch out for:
When a team starts working on an epic (that is “normalized” to story points) by chipping off, estimating, and developing individual user stories, it would also have to ensure that the overall scope does not get inflated because of double booking. For example, if Epic X were initially “normalized” to be 80 story points but then the team chipped away and individually estimated one five-story-pointer and two eight-story-pointers, then it would make sense to “back out” 21 story points from the 80, to keep the overall scope of epic in balance. What could happen by the time that an entire epic is complete is that a cumulative estimation of individual user stories ends up being less than, more than, or adds up to 80 story points (miracle!). As an example, if the final sum of all chipped-off and individually estimated stories turns out to be less than the initial 80, the overall scope would have to be adjusted downward, as it is shown at around weeks eight to nine below:
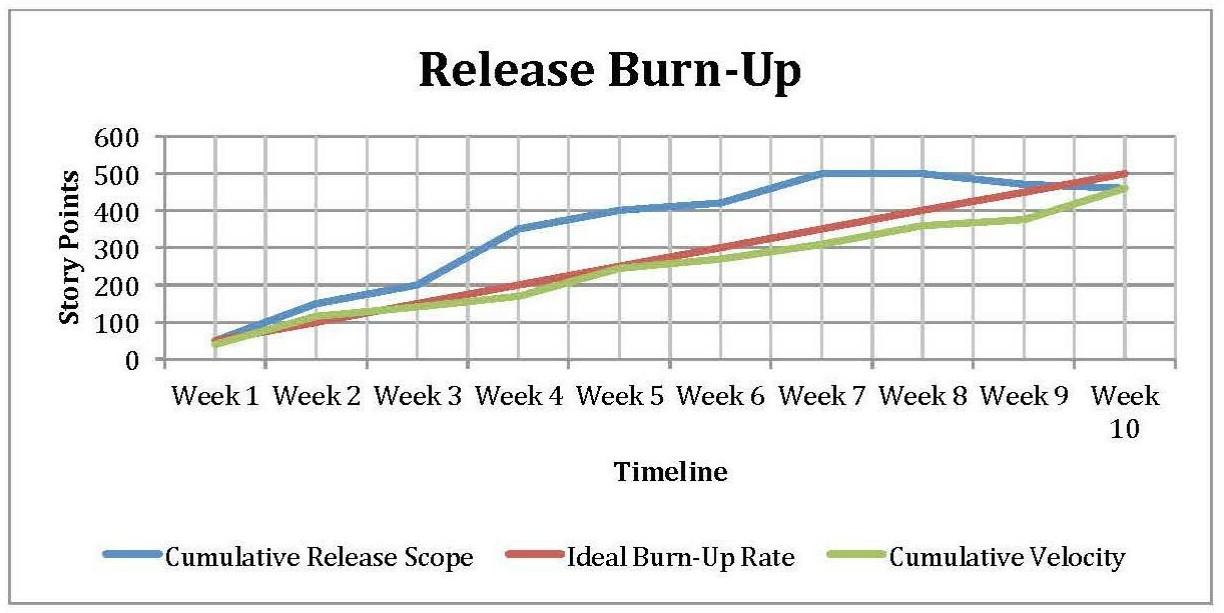
At this point, it is worth nothing that scope decrease (de-scoping) can be done as the team approaches a planned release date for other reasons as well. Among others, a good “Agile reason” why the PO may want to “trim the tail” of scope and deploy sooner is purely a business decision: There is already enough business value in delivered code to justify going to production.
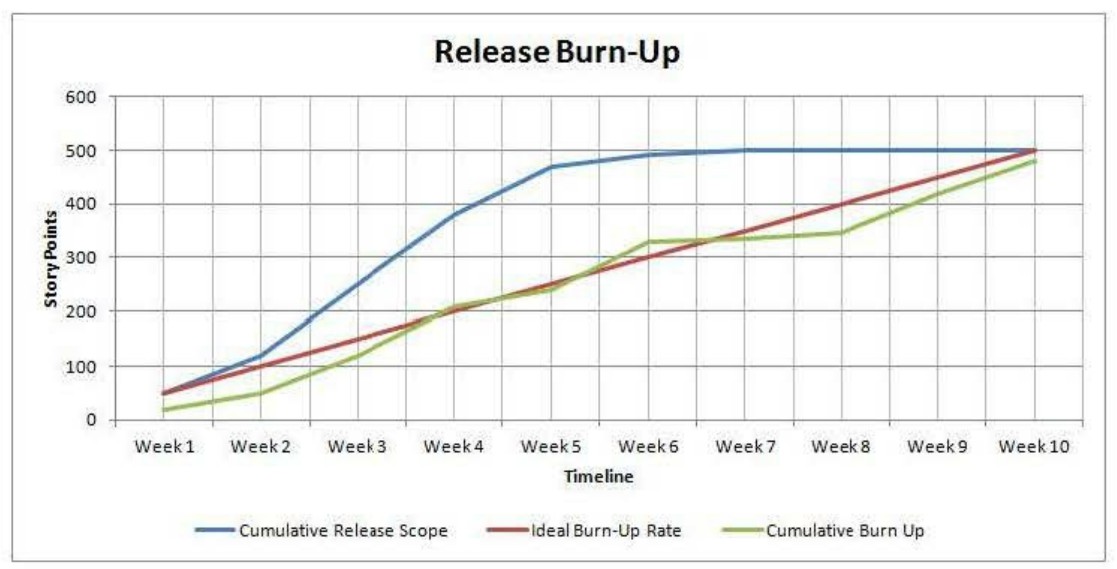
Here is an example of a team that after a period of sprinting has decided to use epic-level estimation and normalization techniques to forecast a multi-sprint release, based on the existing track record of story pointing and well- maintained relationships between overarching epics and underlining stories.
In the diagram below, a noticeable spike in Cumulative Release Scope around Week 4 is due to epic-level normalization to story points and “plugging” them into a release scope:
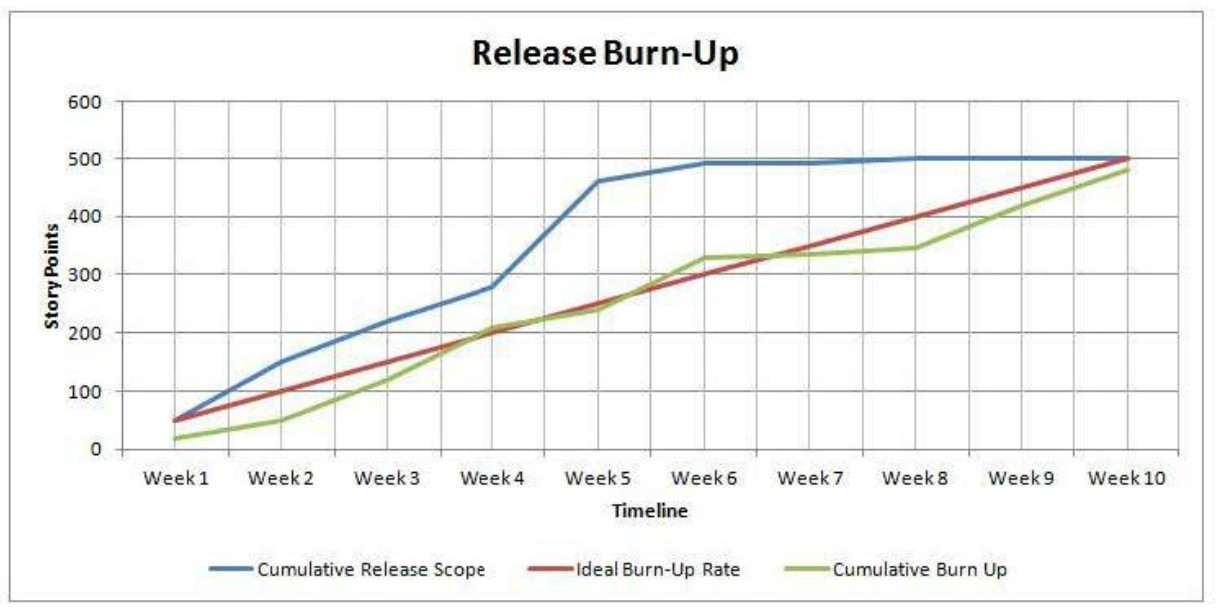
This pretty much sums up the approach. Obviously, to implement it, a team and PO should have some history together: estimating, delivering, having a number decomposed and delivered in full epics, etc. Also, there should be no resource attrition on a team. Having a reliable, continuously engaged PO, whose epic/story writing style remains consistent over time, is another important requirement.